Package Overview
The philosophy of this project is to provide an implementation of AlphaZero that is simple enough to be widely accessible for students and researchers, while also being sufficiently powerful and fast to enable meaningful experiments on limited computing resources.
On this page, we describe some key features of AlphaZero.jl:
- A standalone and straightforward MCTS implementation
- Some facilities for asynchronous and distributed simulation
- A series of opt-in optimizations to increase training efficiency
- Generic interfaces for games and neural networks
- A simple user interface to get started quickly and diagnose problems
Asynchronous and Distributed Simulations
A key aspect of generating self-play data efficiently is to simulate a large number of games asynchronously and batch requests to the neural network across all simulations. Indeed, evaluating board positions one at a time would be terribly slow and lead to low GPU utilization.
Thanks to Julia's great abstractions for asynchronous programming, the complexity of dealing with asynchronous simulations and batching is factored out in a single place and does not affect most of the codebase. In particular, the standalone MCTS module does not have to deal with batching and can be implemented in a straightforward, textbook fashion.
Moreover, leveraging Julia's Distributed module, simulations are automatically distributed over all available Julia processes. This makes it possible to train an agent on a cluster of machines as easily as on a single computer, without writing any additional code. This capability was demonstrated during Julia Computing's sponsor talk at JuliaCon 2020.
Training Optimizations
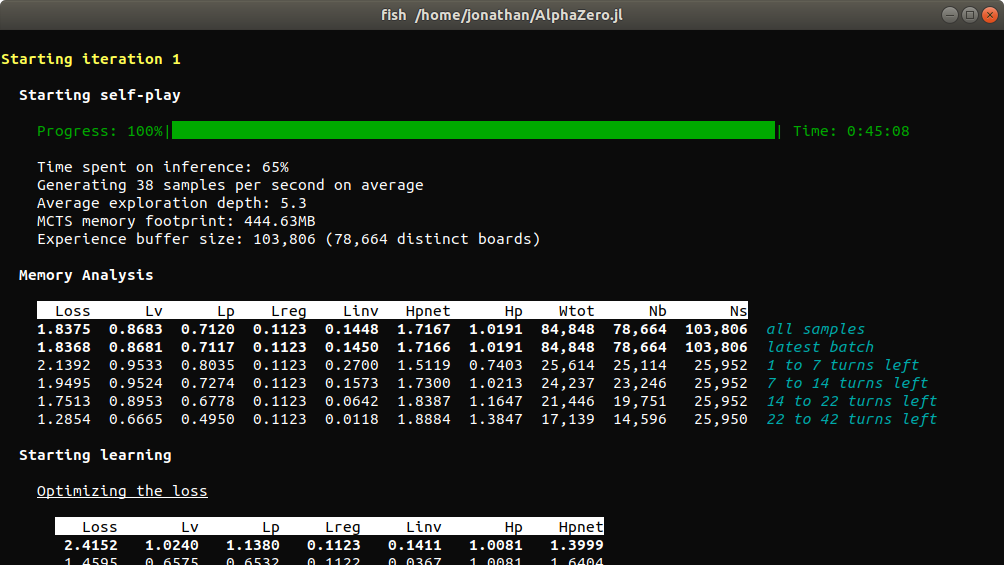
AlphaZero.jl has out-of-the-box support for many of the optimizations introduced in Oracle's series and also implements new ones. These include:
- Position averaging
- Memory buffer with growing window
- Cyclical learning rates
- Symmetry-based data augmentation and game randomization
All these optimizations are documented in the Training Parameters section of the manual.
Game Interface
You can use AlphaZero.jl on the game of your choice by simply implementing the Game Interface. Currently, there is support for two-players, zero-sum games with finite action spaces and perfect information. Support for Markov Decision Processes will be added in a forthcoming release.
Please see here for recommendations on how to use AlphaZero.jl on your own game.
Network Interface
AlphaZero.jl is agnostic to the choice of deep learning framework and allows you to plug any neural network that implements the Network Interface. For convenience, we provide a library of standard networks based on Knet. Right now, it features templates for two-headed multi-layer perceptrons and convolutional resnets.
User Interface and Utilities
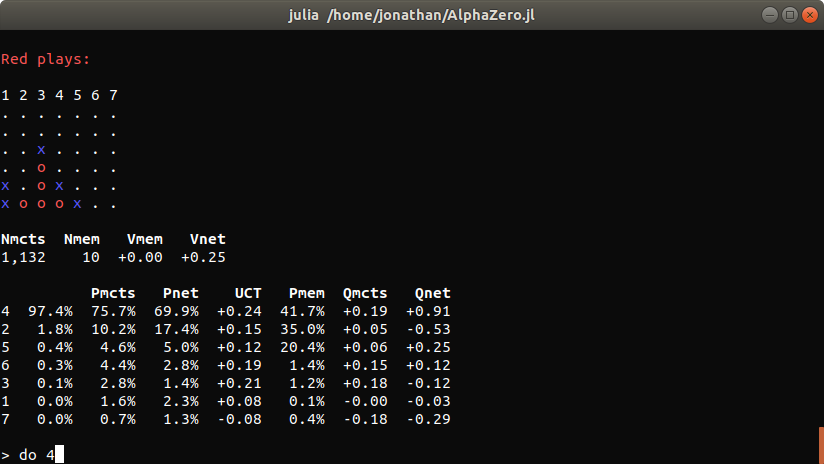
AlphaZero.jl comes with batteries included. It features a simple user interface along with utilities for session management, logging, profiling, benchmarking and model exploration.
- A session management system makes it easy to interrupt and resume training.
- An interactive command interpreter can be used to explore the behavior of AlphaZero agents.
- Common tasks can be executed in a single line thanks to the Scripts module.
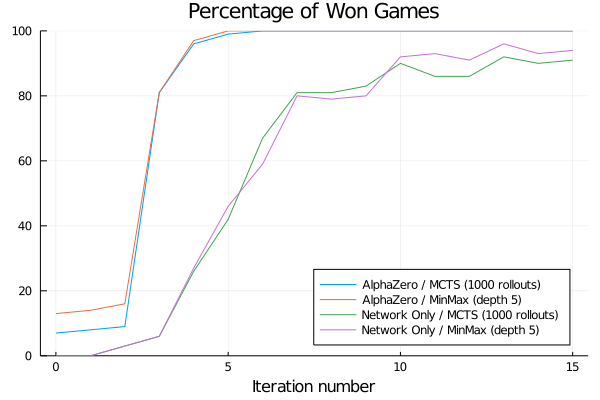
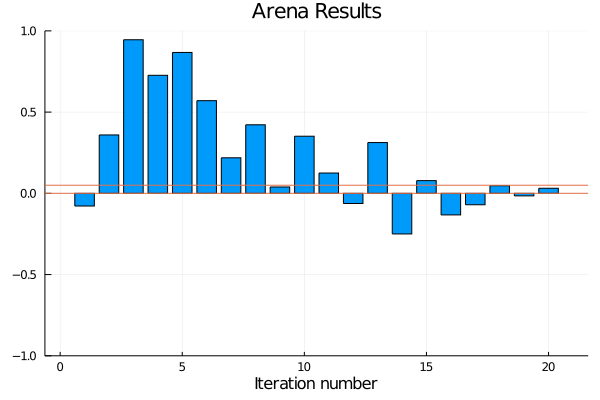
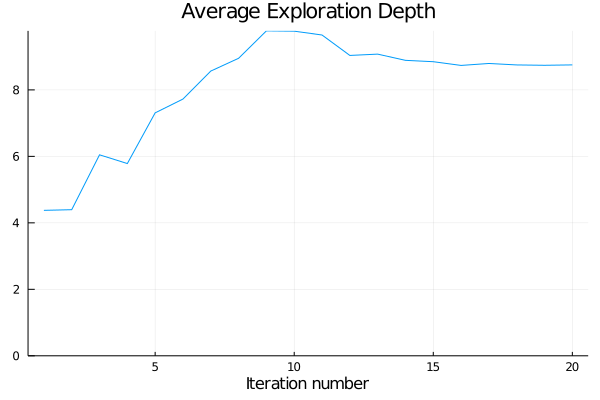
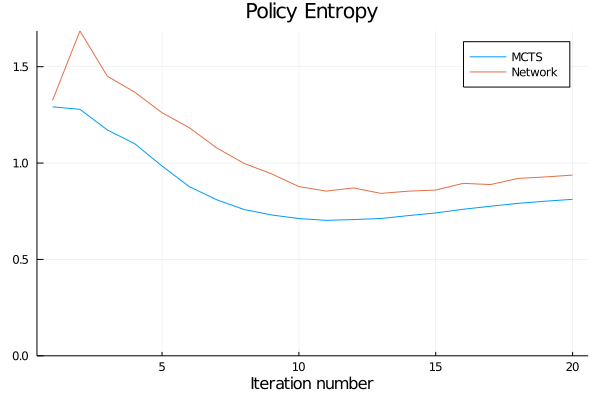
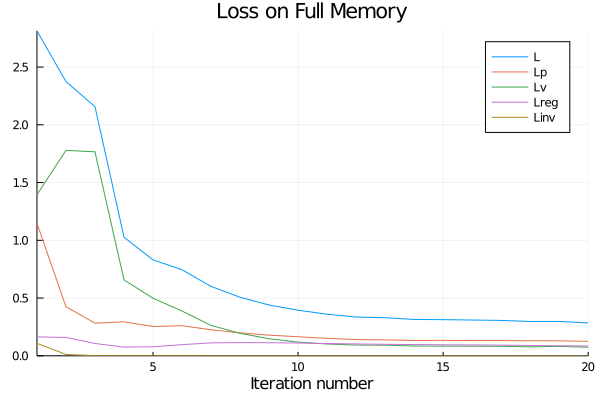
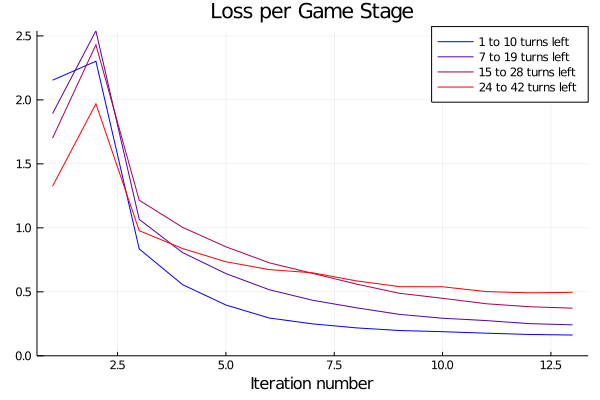
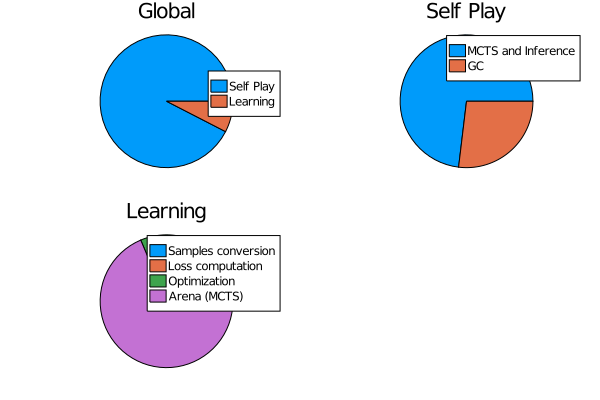
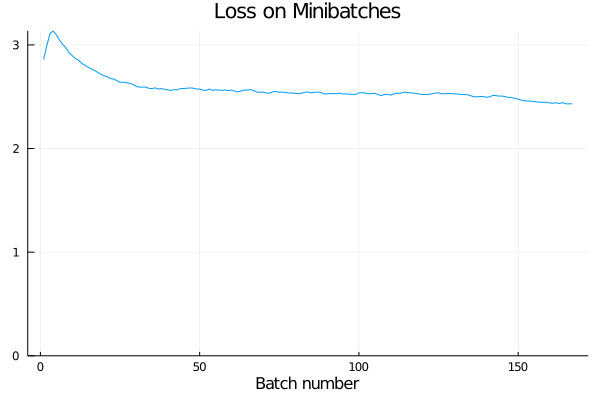
- Reports are generated automatically after each training iteration to help diagnosing problems and tuning hyperparameters. An extensive documentation of collected metrics can be found in Training Reports and Benchmarks.
Finally, because the user interface is implemented separately from the core algorithm, it can be extended or replaced easily.